
티스토리 뷰
- 문제 풀이
https://school.programmers.co.kr/learn/courses/30/lessons/131123
프로그래머스
SW개발자를 위한 평가, 교육, 채용까지 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
기존 작성 답
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM REST_INFO
WHERE (FOOD_TYPE, FAVORITES) IN
(
SELECT FOOD_TYPE, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE
)
ORDER BY 1 DESC
윈도우 함수 적용 답
select sub.food_type, sub.rest_id, sub.rest_name, sub.favorites
from
(
select food_type, rest_id, rest_name, favorites,
row_number() over(partition by food_type order by favorites DESC) as rownum
from rest_info
order by 1, 4 DESC) sub
where sub.rownum = 1
order by 1 DESC
⊙ 윈도우 함수 소개
* 윈도우 함수란?
윈도우 함수는 OVER() 절과 함께 사용하며, 행을 그룹화(PARTITION), 정렬(ORDER BY), 범위 설정(ROWS | RANGE) 하여 다양한 함수들을 제공한다.
-- 윈도우 함수 기본문법
SELECT 윈도우함수(컬럼1) OVER (
[PARTITION BY 컬럼2] -- 그룹화
[ORDER BY 컬럼3 ASC|DESC] -- 정렬
[ROWS|RANGE BETWEEN A AND B] -- 계산 범위
) AS 결과
FROM 테이블;- 윈도우 함수의 진행 순서
- 데이터를 파티션으로 나눔(그룹화)
- 각 그룹별 데이터 정렬
- 정렬된 데이터 내에서 연산범위 설정
- 지정된 범위와 정렬에 따라 윈도우 함수 값 계산
- 윈도우 함수의 특징
- 집계함수의 확장 : SUM, AVG 등의 결과를 개별 행에 표시.
- 기존 집계함수는 그룹 단위로 함수가 적용되지만, 윈도우 함수는 각 행의 데이터와 함께 집계 결과를 유지. 원본 데이터를 유지한 상태에서 집계 결과를 새로운 컬럼으로 만들 수 있는 것이다.
- 원본 데이터 유지 : 원본 데이터와 함께 윈도우 함수의 결과를 동시에 확인 가능
- 다양한 기능의 함수 제공 : 순위 매기기, 누적합 계산, 특정 행 값 참조, 백분위 계산 등등
- 윈도우 실행 순서
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → [윈도우 함수] → SELECT → DISTINCT → ORDER BY → LIMIT
⊙ 윈도우 함수 종류
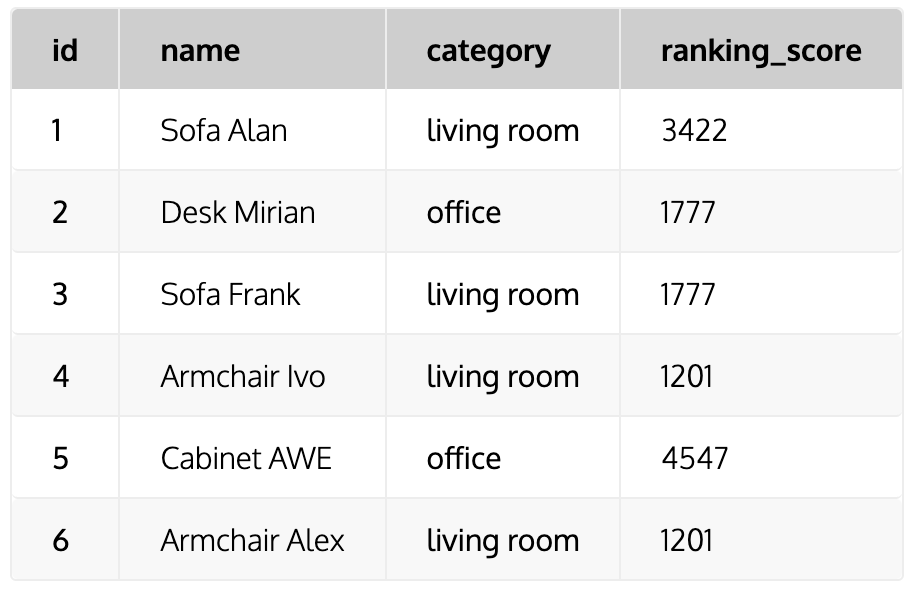
테이블명: Product
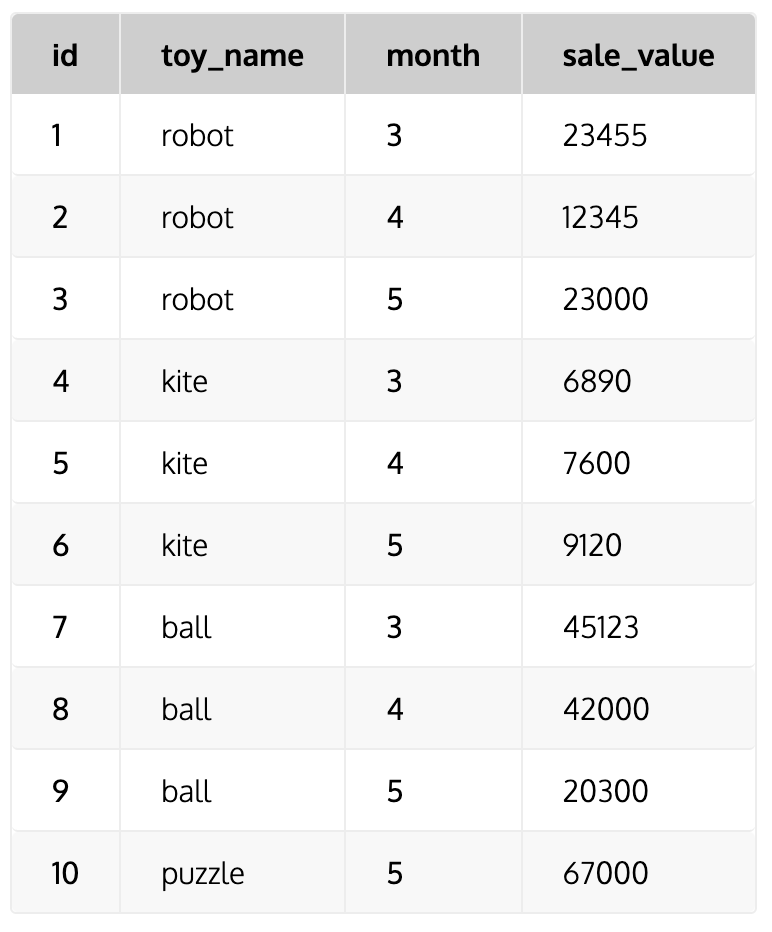
테이블명: toy_sales
* 순위 함수 : rank(), dense_rank(), row_number()
- RANK() : 순위를 매기되, 동일한 값에 대해 같은 순위를 부여한다. 이후 순위를 건너뜀
SELECT RANK() OVER(ORDER BY ranking_score) AS rank_number,
name, category, ranking_score
FROM product
쿼리 결과

SELECT RANK() OVER (PARTITION BY category ORDER BY ranking_score) AS rank_number,
name, category, ranking_score
FROM product
쿼리결과 : 카테코리 별로 나누어 랭킹을 구분함

- DENSE_RANK() : 동일한 값에 대해 같은 순위 부여. 다음 순위는 건너뛰지 않는다.
SELECT DENSE_RANK() OVER(ORDER BY ranking_score DESC) AS dense_rank_number,
name, category, ranking_score
FROM product
쿼리결과

- ROW_NUMBER() : 동일한 값에도 고유한 순위를 부여
SELECT ROW_NUMBER() OVER(ORDER BY ranking_score) AS row_number,
name, category, ranking_score
FROM product
쿼리결과 : 전체를 파티션으로 보고 순위를 매긴 것. score가 같아도 순위를 다르게 매기는 이유는 행 번호이기 때문에.

* 집계 함수
- sum() : 그룹화된 데이터(파티션 내)에 대해 누적합 계산
SELECT toy_name, month, sale_value,
SUM(sale_value) OVER(PARTITION BY toy_name ORDER BY month)
AS total_toy_value
FROM toys_sale
쿼리결과

* 행 참조 함수 : lag(), lead()
- lag() : 이전 행 참조
SELECT toy_name, month, sale_value,
lag(sale_value) OVER(PARTITION BY toy_name ORDER BY month)
AS prev_month_value,
lag(sale_value) OVER(PARTITION BY toy_name ORDER BY month) - sale_value
AS difference
FROM toys_sale
쿼리결과

+ NULL 과의 연산은 결과가 NULL이 나온다. (IFNULL 함수로 처리해줄 수 있다)
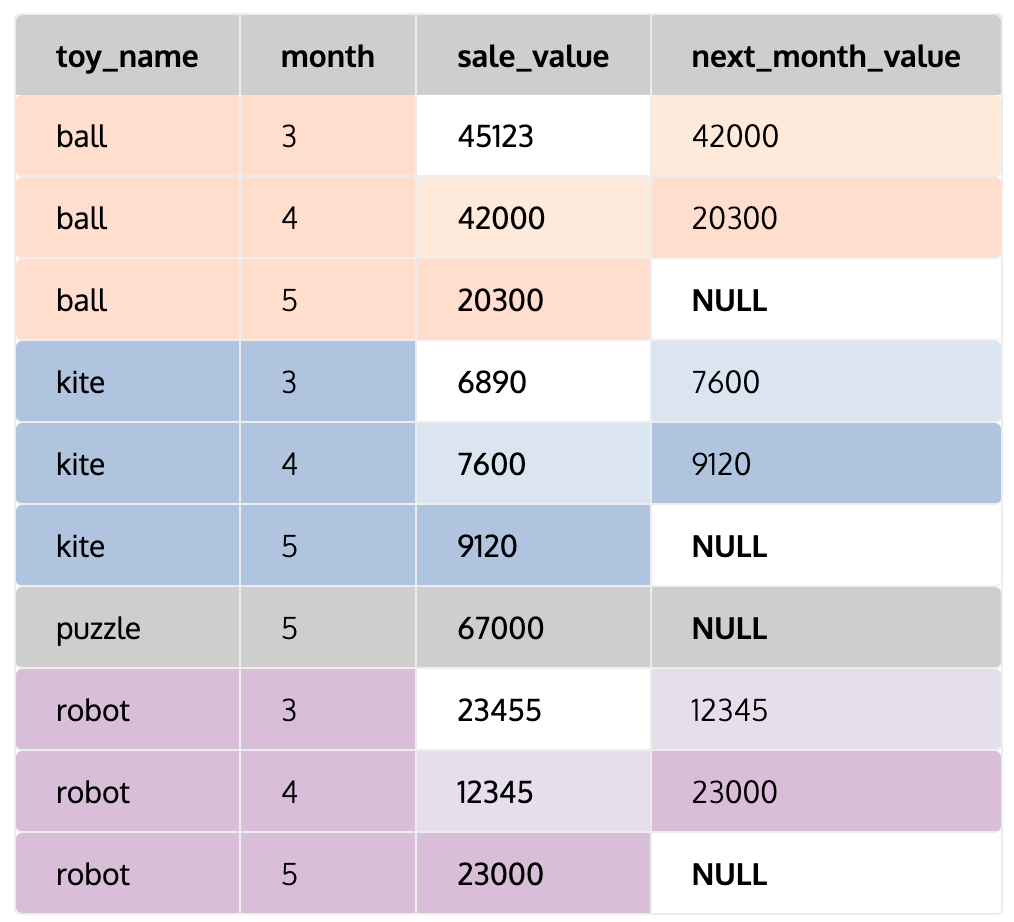
- lead() : 다음 행 참조
SELECT toy_name, month, sale_value,
LEAD(sale_value) OVER(PARTITION toy_name ORDER BY month)
AS next_month_value
FROM toys_sale
쿼리결과
* 비율 함수 : percent_rank()
- percent_rank() : 데이터의 백분위 순위를 계산
예제 1
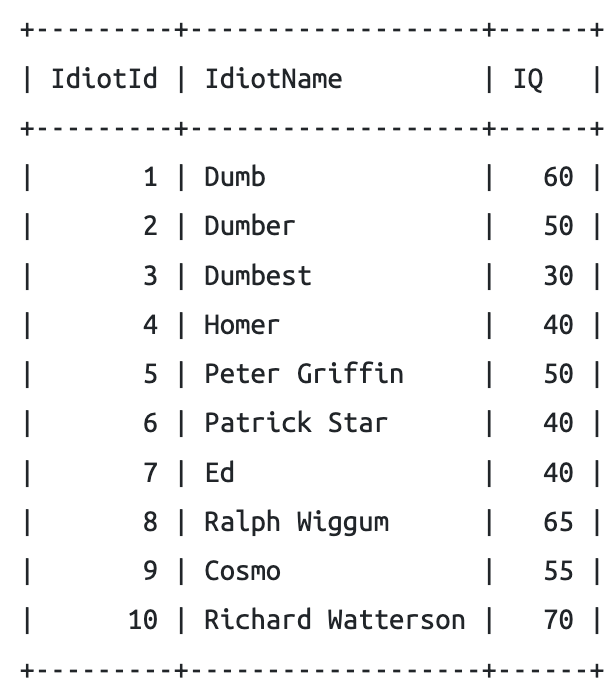
SELECT IdiotName, IQ,
percent_rank() OVER(ORDER BY IQ) AS "Percentage RANK"
FROM Idiots
쿼리결과
+-------------------+------+--------------------+
| IdiotName | IQ | Percentage Rank |
+-------------------+------+--------------------+
| Dumbest | 30 | 0 |
| Homer | 40 | 0.1111111111111111 |
| Patrick Star | 40 | 0.1111111111111111 |
| Ed | 40 | 0.1111111111111111 |
| Dumber | 50 | 0.4444444444444444 |
| Peter Griffin | 50 | 0.4444444444444444 |
| Cosmo | 55 | 0.6666666666666666 |
| Dumb | 60 | 0.7777777777777778 |
| Ralph Wiggum | 65 | 0.8888888888888888 |
| Richard Watterson | 70 | 1 |
+-------------------+------+--------------------+
예제 2
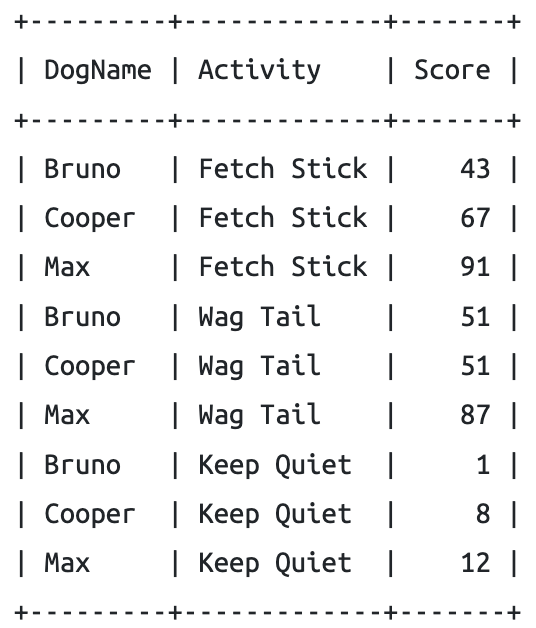
SELECT DogName, Activity, Score,
PERCENT_RANK() OVER(PARTITION BY Activity ORDER BY Score ) AS "Percentage Rank"
FROM Dogs
쿼리결과
+---------+-------------+-------+-----------------+
| DogName | Activity | Score | Percentage Rank |
+---------+-------------+-------+-----------------+
| Bruno | Fetch Stick | 43 | 0 |
| Cooper | Fetch Stick | 67 | 0.5 |
| Max | Fetch Stick | 91 | 1 |
| Bruno | Keep Quiet | 1 | 0 |
| Cooper | Keep Quiet | 8 | 0.5 |
| Max | Keep Quiet | 12 | 1 |
| Bruno | Wag Tail | 51 | 0 |
| Cooper | Wag Tail | 51 | 0 |
| Max | Wag Tail | 87 | 1 |
+---------+-------------+-------+-----------------+
⊙ 파티션 범위 지정
* 파티션 범위 지정하는 이유

윈도우 함수의 범위는 ROWS 혹은 RANGE를 사용하여 지정한다.
윈도우 함수에서 범위를 지정하는 이유는 분석을 수행할 데이터의 범위를 명확히 설정하여, 특정 행이 분석 결과에 어떤 방식으로 포함될지 결정하기 위해서이다. 범위를 지정해서 동일한 데이터에 대해 다양한 분석을 할 수 있고 필요한 결과를 정확하게 도출할 수 있다.
* 범위 옵션
- UNBOUNDED PRECEDING : 윈도우의 시작부터 현재 행까지 계산 (기본값)
- CURRENT ROW : 현재 행까지 계산
- N PRECEDING : 현재 행에서 N개의 이전 행까지 계산
- N FOLLOWING : 현재 행에서 N개의 이후 행까지 계산
- BETWEEN A AND B : A에서 B까지의 범위를 지정하여 계산
- UNBOUNDED FOLLOWING : 윈도우의 끝까지 계산

* 예시
- 고객별 누적 결제 금액 계싼
SELECT 고객ID, 결제ID, 결제금액,
SUM(결제금액) OVER(PARTITION BY 고객ID ORDER BY 결제ID) AS 누적결제금액
FROM payments
쿼리결과

* 예시 2
- 고객별 최근 두 결제건에 대한 평균 금액 계산
SELECT 고객ID, 결제ID, 결제금액,
AVG(결제금액) OVER(PARTITION BY 고객ID ORDER BY 결제ID ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS avg_rec_paid
FROM payments
쿼리결과

'세션 복습 > SQL 세션' 카테고리의 다른 글
| [8일차] SQL 라이브 세션 6 - 개인 과제 퀴즈 (0) | 2025.01.14 |
|---|---|
| [7일차] SQL 참고 자료 (0) | 2025.01.13 |
| [6일차] SQL 라이브 세션 4 (1) | 2024.12.09 |
| [4일차] SQL 라이브 세션 3 (1) | 2024.11.29 |
| [3일차] SQL 라이브 세션 2 (1) | 2024.11.27 |